3. Input¶
3.1: CSV of Ensembl transcript IDs and arguments¶
In this first option a .csv table of Ensembl transcript IDs and optional arguments is used. Except for the first column indicating the Ensembl transcript id, any argument can be left blank which will result in the default value being used. An example of this file is included in the sample_analysis folder and can be downloaded from Github.
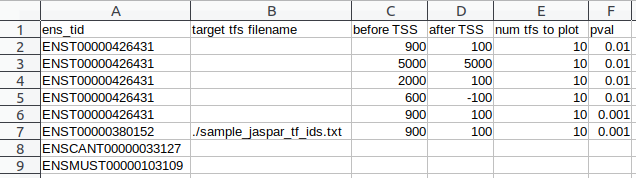
3.2: Text file of IDs¶
In this second option a simple text-file of Ensembl transcript IDs is used. Whatever arguments are provided to the command-line will be applied to analysis of all transcripts indicated in this file. An example of this file is included in the sample_analysis folder and can be downloaded from Github.
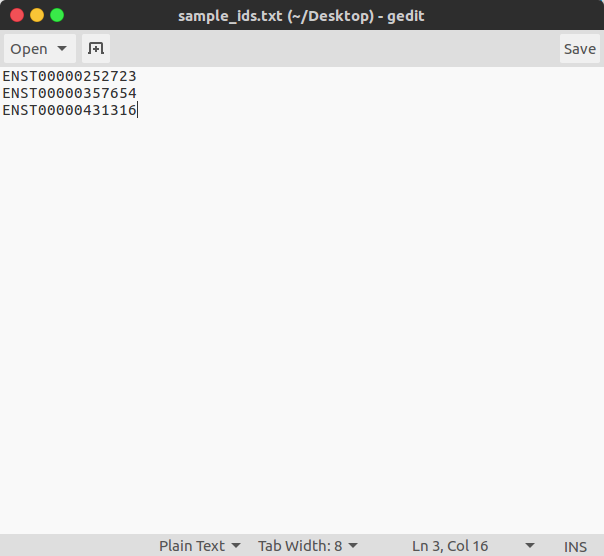
3.3: Text file TF IDs¶
A file of JASPAR TF IDs can be provided which will limit the analysis of TFs to just those contained within. If no file name is provided then the analysis will use all 575 JASPAR TFs in the analysis, in this case the results in the output table can be filtered to just those TFs you wish to focus on. An example of this file, which contains all JASPAR TF IDs, is included in the sample_analysis folder which can be downloaded from Github.